Overview
The businesses worldwide are rapidly joining the AI race, and Khrystodulov Consult is not an exception. The current wave of AI has brought thousands of ready-to-use tools to the market, but for companies the real challenge is not whether to use them or not, but it is how to stay ahead and remain competitive within the landscape. Today, success depends on making faster decisions, automating processes wherever practical, reducing risk, and lowering operational costs.
The challenge
The challenge had several interconnected dimensions. The company needed a way to make strategic decisions faster, while protecting sensitive internal knowledge and maintaining a reliable system for aggregating legal, technical, and business research. The goal was not only to improve access to information, but to do so in a way that remained structured, traceable, and suitable for real decision-making.
Here how the questions were structured:
- “How to take strategic decisions faster?”
- “How not to expose company’s secrets and findings?”
- “How to maintain internal and external business knowledge efficiently”?
- “What tools to use?”
- “Is it reliable?”
There are many tools and methods, including commercial and open-source solutions, aimed at supporting knowledge management, such as Notion, Jira, Obsidian, Google Docs, Gemini, Microsoft Word, Markdowns etc.. Choosing among them, while considering coverage of business objectives, scalability, subscription price, and maintainability, becomes a real research among hundreds of tools with potential budget spends on data integrations and preparation requirements in case the tool do not support integration natively.
Objectives
The objective was to build a practical internal knowledge base that could turn fragmented business information into a structured, searchable, and reusable decision-support environment. This required more than simply storing documents in one place. The system needed to digitalize existing materials, integrate knowledge from multiple sources, and make that knowledge accessible in a form that could support real operational and strategic work.
A key objective was to bring together knowledge from Google Docs, website links shared, pdf research documents, and other internal materials into a single environment while preserving traceability and clearly distinguishing which sources should be treated as the source of truth. This was essential to avoid confusion, reduce duplication, and ensure that internal decisions were based on reviewed and trusted information rather than scattered notes or outdated versions.
The knowledge base also needed to support simple but high-value interactions between a human user and the system. The aim was to make it possible for an operational manager or decision-maker to ask practical questions such as:
• “What did we promise in Proposal X”
• “What are the milestones of Project Y”?
• “Create a draft of the new proposal for entity Z”
Solution
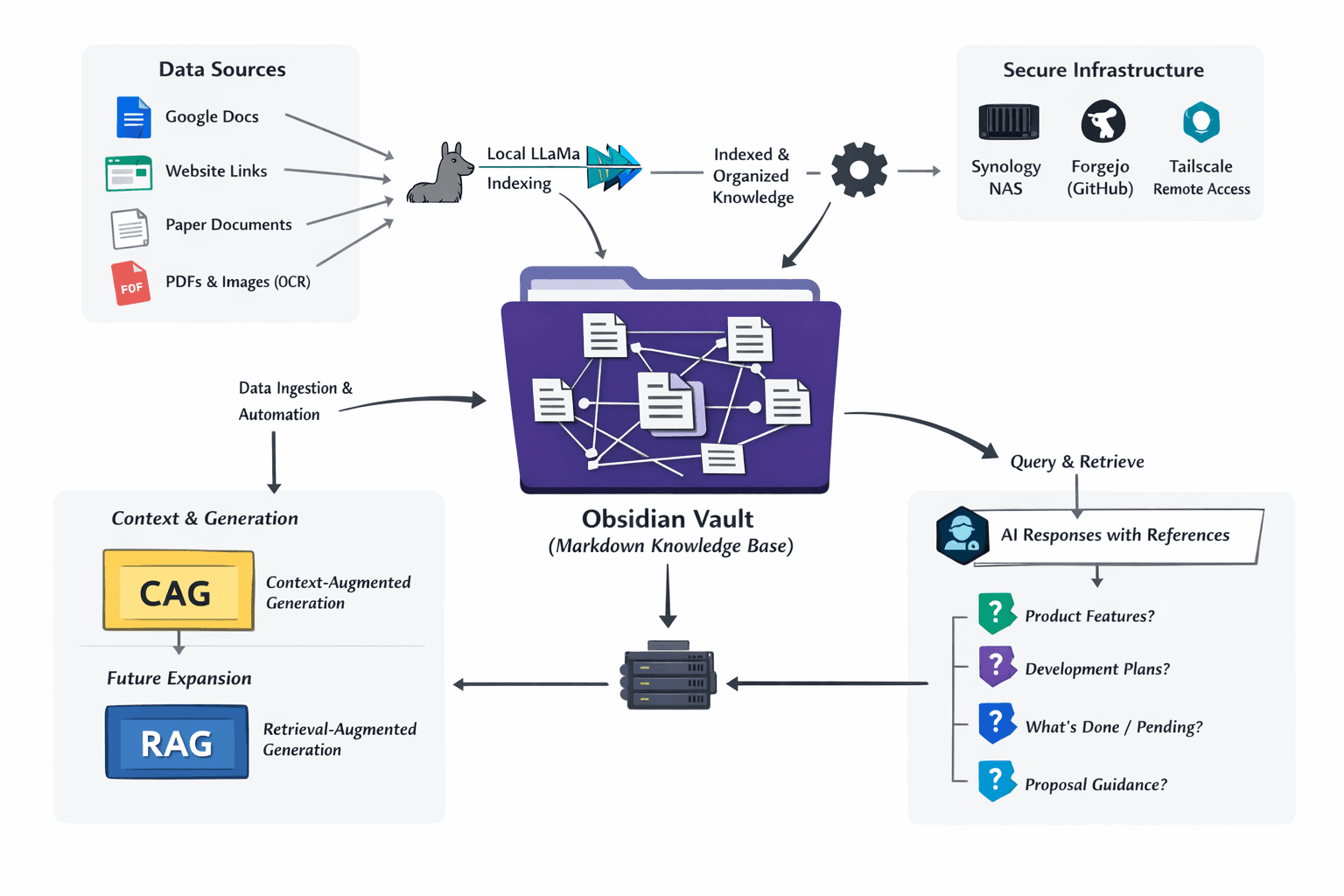
The solution was built on secure internal infrastructure designed to support both the company’s knowledge workflows and its broader technical operations. A Synology NAS served as more than storage for large Earth Observation datasets company had, but it also hosted Docker containers running the company’s internal services, including a self-hosted Forgejo instance used for repository management and knowledge version maintenance.
Secure access was enabled through Tailscale, allowing team to connect from anywhere without the overhead and complexity of traditional VPN setups. This made the knowledge environment easier to access in practice while keeping sensitive internal information under company control.
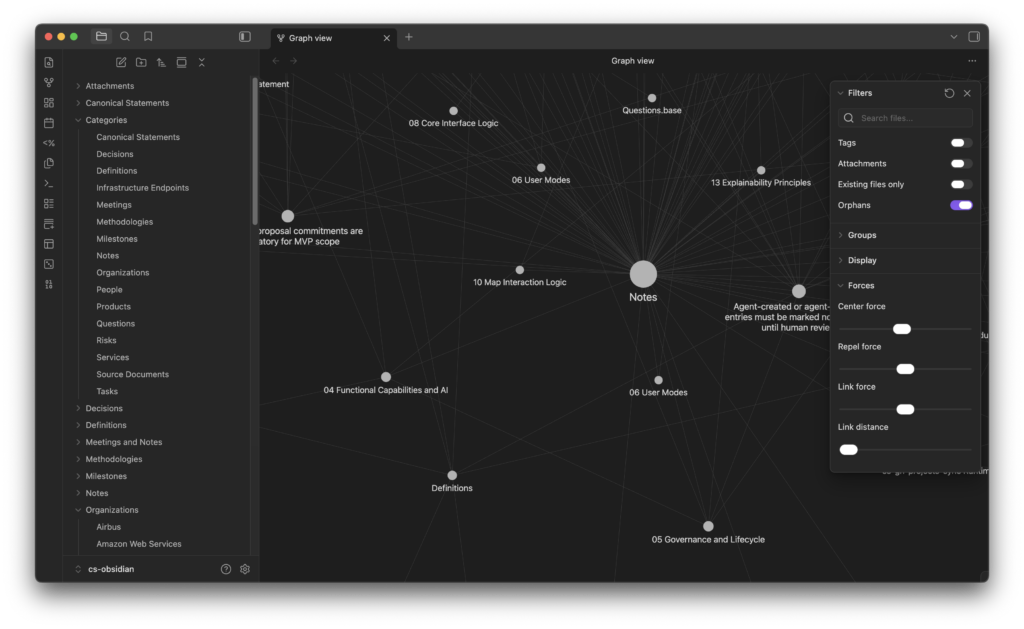
At the core of the solution was a dedicated knowledge-base repository hosted in Forgejo and maintained as an Obsidian Vault built on structured Markdown files. This provided a sustainable and maintainable foundation for long-term knowledge management, avoiding unnecessary dependence on commercial tools while keeping information portable, version-controlled, and human-readable.
Obsidian Bases added an additional layer of structure, making knowledge easier to organize, connect, and review across legal, technical, and product-development contexts.
The solution also included a broader information-processing pipeline. OCR was used to extract text from PDFs and images, while automations collected knowledge from sources such as Google Docs and website links. Once collected, the information was structured, indexed using Llama, and prepared for retrieval through AI-supported workflow. This made it possible to move from scattered materials and static files to a searchable and reusable internal knowledge system.
For the current stage, the implementation was designed primarily around a CAG-oriented approach, where structured and curated context could be supplied directly from reviewed knowledge assets. This made the system well suited for controlled internal use, where traceability and human oversight were critical. At the same time, the architecture leaves room for future RAG-style expansion, allowing retrieval pipelines to grow further as the knowledge base, source volume, and use cases become more complex.
Several practical benefits followed from this approach.
- Knowledge remained version-controlled through Git, making changes transparent and recoverable over time.
- Notes could be clearly distinguished as reviewed or not reviewed, with each item assigned an owner and status, helping maintain accountability and trust in the system.
- Proposal writing time decreased twice
- Easier onboarding
Together, these elements created a structured, secure, and scalable environment in which internal knowledge could be maintained more reliably and used more effectively in strategy, product shaping, and operational decision-making.

